InnoEval:当AI也组了一个"评审委员会",它比人类审稿人更靠谱吗?
一句话总结:InnoEval把"给论文打分"这件事,拆解成了"搜资料→对证据→多人评审→投票表决"的完整链条,用异构知识搜索引擎+虚拟评审团+五维度解耦评分,在NeurIPS/ICLR真实审稿数据上把三分类F1干到了74.56%,和人类专家的维度相关性最高达0.80。
🎯 一个尴尬的现状:AI造想法比评想法快多了
过去两年,大模型在科研领域的渗透速度惊人。自动文献综述、自动生成研究想法、自动设计实验方案——这些工具让"产出想法"变得极其廉价。但问题随之而来:谁来判断这些想法靠不靠谱?
人类审稿人显然来不及。顶会的审稿周期从投稿到出结果往往要三四个月,每篇论文至少需要3位审稿人花数小时仔细阅读。当AI一天能产出几十个研究方案时,人类审稿流程直接变成了系统的瓶颈。
那让AI来审?LLM-as-a-Judge这条路已经有不少人走了,但效果差强人意。问题出在哪?
知识量不对等。一个经验丰富的审稿人在评审之前,脑子里已经装了这个领域几百篇论文的知识地图。碰到不熟悉的方向,还会花时间去Google Scholar上搜几篇相关工作对比着看。而直接让LLM打分,等于让它做闭卷考试——它只能依赖训练时见过的内容,对于最新发表的、还没来得及更新到参数里的工作一无所知。
视角太单一。真实的同行评审是什么样?三到五个背景各异的审稿人独立评审,有人从理论角度挑方法的漏洞,有人从工程角度质疑可行性,有人从应用前景判断影响力。这种多视角碰撞正是评审机制的精髓。而单个LLM的评审更像"一言堂"——它的偏好、它训练数据的分布、它对某些关键词的敏感度,全部一股脑映射到最终判断上,没人制衡。
维度太粗糙。一篇论文到底好不好?"好"这个字太含糊了。审稿人在OpenReview上打分,是分Soundness、Novelty、Clarity、Significance分别评的。一篇论文可能方法很新但写得稀烂,也可能写得漂亮但贡献不大。把这些维度揉成一个总分,就像用一个数字评价一个人——几乎注定会丢失关键信息。
InnoEval这篇论文的出发点很明确:不要把想法评估当成"打分问题",而是当成一个需要搜集证据、组织多方观点、在多个维度上独立推理的复杂认知任务。
说白了,作者想造一个AI版的"评审委员会"——不是一个模型一次性给出答案,而是一群"角色各异的虚拟审稿人"在充分查阅文献后,各自给出独立的多维度评审意见,再通过共识机制得出最终判断。
这个想法本身就很有意思:如果人类用委员会制度来保证评审公正,那AI为什么不可以?
📖 论文基本信息
- 标题:InnoEval: On Research Idea Evaluation as a Knowledge-Grounded, Multi-Perspective Reasoning Problem
- 作者:Shuofei Qiao, Yunxiang Wei, Xuehai Wang 等(浙江大学)
- 链接:https://arxiv.org/abs/2602.14367
- 发表时间:2026年2月
🏗️ InnoEval:一套完整的AI评审流水线
先看全景图:
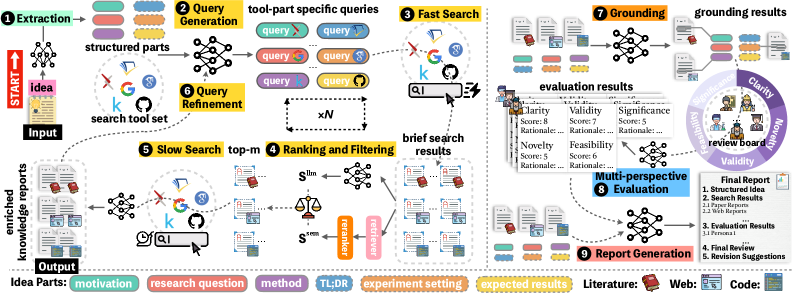
图1:InnoEval的九步工作流水线。从左侧输入一个研究想法(分解为motivation、research question、method等六个结构化部分),经过查询生成→快速搜索→排序过滤→慢速搜索→查询精炼(迭代N次)→知识对齐→多视角评估(虚拟评审团在Clarity/Novelty/Validity/Feasibility/Significance五个维度上独立打分)→报告生成,最终输出一份结构化的评审报告。搜索覆盖文献(arXiv、Semantic Scholar、Google Scholar)、网页(Google Search)和代码(GitHub、Kaggle)三类异构数据源。
这张图包含的信息量很大,拆开来看整个流程分为四大块:
第一块:异构深度知识搜索——让AI真正"查资料"
这是InnoEval和普通LLM-as-Judge最本质的区别。想象一下人类审稿人的工作流程:拿到一篇论文,先看标题摘要有个大概印象,然后根据核心方法去Scholar上搜相关工作,看到几篇关键论文后再细读,读完又想到新的关键词继续搜……这个过程不是线性的,而是螺旋上升的。
InnoEval用"快搜+慢搜+迭代精炼"来模拟这个过程。
快速搜索阶段,系统先把输入的研究想法拆成六个结构化部分——TL;DR、研究动机、研究问题、方法、实验设置、预期结果。针对每个部分,搜索代理生成一批查询语句,然后在三类异构数据源上并行检索。为什么要分这么细?因为"一个关于强化学习的想法"和"用PPO训练reward model"的检索策略完全不同——前者太宽泛,后者才能找到精准的对照方法。
检索结果用一个混合评分函数过滤,公式很直觉:
语义相似度管"相关不相关",LLM评分管"有没有用"。用embedding算的相似度速度快但粗糙,LLM判分更准但成本高——两者互补。
慢速搜索阶段,快速搜索拿到的只是标题和摘要级别的信息。慢速搜索把排名靠前的结果"读全文"——文献下载PDF提取方法和实验细节,网页抓取完整内容,代码仓库分析结构、README和核心实现。读完之后,系统把碎片化的搜索结果整合成一份"知识报告"。
迭代精炼是最精妙的部分。搜索代理看过已经获取的知识后,会对查询进行三种操作:重写(更精确)、泛化(扩大范围)、具体化(聚焦子问题)。这个过程重复N次,越搜越深。就像你写综述时的体验——读了第一批论文后突然发现一个新的关键术语,顺着这个术语又挖出一批之前没找到的工作。InnoEval把这种"越搜越会搜"的人类行为系统化了。
为什么搜索范围要扩展到网页和代码?这是一个很实际的考虑。有些研究想法的可行性不光取决于理论上是否说得通,还取决于——有没有现成的代码实现可以参考?GitHub上有没有人已经在做类似的事情?Kaggle上有没有现成的数据集?这些信息在传统文献检索中是找不到的。
第二块:知识对齐——"这条证据到底在说什么"
检索到一堆资料只是第一步。关键问题是:哪条证据支撑了想法的哪个部分?哪条证据其实在唱反调?
很多现有方法的做法很粗暴——搜到10篇相关论文,全部拼接到prompt里交给LLM"请参考以上资料进行评估"。这等于让审稿人在桌上堆了一摞论文,但不告诉他哪篇是需要重点对比的baseline,哪篇其实已经把这个方法否定了。
InnoEval的做法是细粒度对齐。对想法的每个结构化部分(比如"方法"),系统会从所有检索到的知识中: 1. 提取与这部分直接相关的证据片段 2. 标注每条证据的立场——是支持、反驳,还是提供补充信息 3. 评估证据的相关性强度
打个比方,如果有人说"我要用MCTS来优化大模型的推理路径",对齐模块会把检索到的论文分成几类:有的论文证明MCTS在类似场景确实有效(支持方法可行性),有的论文指出MCTS的搜索空间在长序列上会爆炸(质疑可行性),有的论文提出了替代方案(提供baseline对比)。这种精细的映射关系让后续评估有据可依,而不是"大概看了看觉得还行"。
第三块:虚拟评审委员会——五维度 × 多角色
这是整个框架最核心的设计。
角色设计。系统预定义了一批学术人物角色,每个角色有三个属性: - 学术身份(资深教授 / 助理教授 / 高年级博士生 / 工业界研究员 / 研究工程师等) - 领域专业度(某些领域熟悉、某些领域了解皮毛) - 评审偏好(有的严格挑刺、有的宽容鼓励,有的关注方法创新、有的关注实验扎实度)
评估时,系统随机抽取若干角色组成"评审委员会"。每个角色看到的知识还会做部分掩码——这个设计特别巧妙。现实中,一个做NLP的审稿人去审一篇CV的论文,他不可能了解CV领域所有最新工作。知识掩码模拟的就是这种"信息不对称",让不同角色的评审意见自然产生差异。
五维度解耦评估。每个角色在以下五个维度上独立评分:
| 维度 | 评估的核心问题 | 举例 |
|---|---|---|
| Clarity(清晰度) | 想法表述是否清楚完整? | 方法描述是否有歧义?实验变量是否定义清楚? |
| Novelty(新颖性) | 和已有工作的差异在哪? | 核心贡献是否只是换了个数据集?还是提出了全新的范式? |
| Validity(有效性) | 方法在理论上能否解决目标问题? | 假设是否合理?推导是否有漏洞? |
| Feasibility(可行性) | 技术上能否实现? | 需要多少GPU?数据集够不够?训练时间是否可接受? |
| Significance(重要性) | 影响力有多大? | 解决的是核心问题还是边缘问题?有没有推广价值? |
为什么要解耦?因为一篇论文在不同维度上的表现可能天差地别。一个想法可能极具新颖性(Novelty满分),但技术上根本做不到(Feasibility零分)。把五个维度揉成一个总分会掩盖这种差异,而解耦评估让问题暴露得更彻底。
每个角色对五个维度分别写评审意见、给出分数和理由。所有角色评审完成后,通过共识机制(类似元评审员Meta-reviewer的角色)整合多个视角的意见,得出最终判断。
这个设计和人类评审制度几乎是一一对应的——多个审稿人独立评审 → Area Chair综合意见 → 做出最终决定。
第四块:报告生成——三种评估模式
InnoEval支持三种场景:
- Point-wise(点评):对单个研究想法输出完整评审报告,包含五维度评分、综合评价、修改建议,以及最终决策(Reject/Poster/Spotlight/Oral)
- Pair-wise(对比):给定两个想法,判断哪个更好,并解释原因
- Group-wise(排序):对一组想法做全排序,生成横向对比分析
其中Group-wise最难——不像Point-wise只看一个,也不像Pair-wise只比两个,你需要在全局视角下衡量多个想法的相对位置,既要考虑绝对质量也要考虑相对优势。
🧪 实验:在真实会议审稿数据上验证
论文的实验设计很扎实,数据集直接来自NeurIPS 2025和ICLR 2025。
数据集构建
| 数据集 | 规模 | 任务描述 | 来源 |
|---|---|---|---|
| Point-wise | 217个样本 | 预测论文的会议最终决定(4类:Reject/Poster/Spotlight/Oral,或简化为2类/3类) | NeurIPS 2025 + ICLR 2025 |
| Pair-wise | 372对 | 判断哪个想法更好;分"简单对"和"困难对" | 从Point-wise采样 |
| Group-wise | 172组 | 从一组相似想法中选出最佳,或做全排序 | 按主题聚类构建 |
"简单对"和"困难对"的区分很有意思——如果两个想法的质量差距很大(比如一个Oral一个Reject),那判断很容易;但如果两个都是Poster级别,要分出高下就难多了。这个设计能更细致地检验评估方法的区分能力。
主要结果
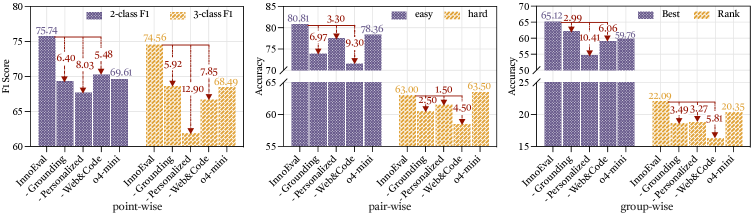
图3:InnoEval在Point-wise(左)、Pair-wise(中)、Group-wise(右)三种任务上的表现,以及移除各模块后的性能变化。左侧面板:点评任务的二分类F1达到75.74%,三分类F1达到74.56%;中间面板:成对比较在"简单对"和"困难对"上的准确率;右侧面板:组排序任务的best accuracy(65.12%)和rank accuracy。o4-mini baseline作为对照。每个面板都展示了移除Grounding(知识对齐)、Personalized(多角色个性化)、Web&Code(网页和代码数据源)后的性能下降。
几个关键数字:
Point-wise:三分类F1达到74.56%,比最强baseline o4-mini高出16.18个百分点。二分类F1 75.74%——考虑到人类审稿人之间的一致性往往也就70%多,这个数字已经非常接近人类水平了。
Pair-wise:在"困难对"上的提升特别明显。容易分辨的高下之别,谁都能判断;难分伯仲的时候才见真功夫。InnoEval在困难对上的准确率领先约5个百分点。
Group-wise:best accuracy 65.12%,rank accuracy也优于baseline。组排序任务的难度最高,因为需要在多个相似想法中建立全序关系,而不是简单的二元判断。
消融实验揭示了什么?
从图3的消融结果可以清楚看到三个关键模块各自的贡献:
移除知识对齐(w/o Grounding):性能下降,但幅度相对温和。这说明"有知识"比"精准匹配知识"更重要——只要搜到了相关资料,LLM在一定程度上能自己建立关联。但知识对齐让这个过程更高效、更准确。
移除多角色个性化(w/o Personalized):性能下降幅度最大。这个结果很能说明问题——去掉多角色,InnoEval就退化成了一个增强版的LLM-as-Judge。多角色评审不是锦上添花,而是核心竞争力。从另一个角度想,这也验证了"单一LLM评审确实有系统性偏见,而多角色机制能有效对冲"这个假设。
移除网页和代码搜索(w/o Web&Code):性能也有明显下降,尤其在Group-wise任务上。这符合直觉——当你要横向对比多个想法时,仅靠文献信息不够,还需要知道每个方法在工程上是否可行、有没有开源实现、社区反馈如何。网页和代码数据源恰好补上了这块拼图。
和人类专家的维度级相关性
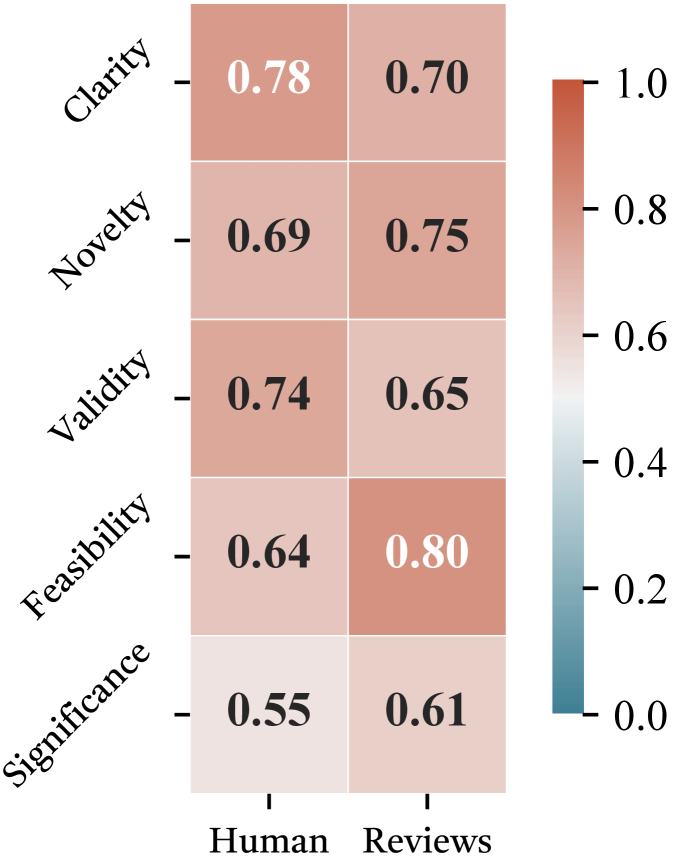
图2:InnoEval各维度评分与人类专家评审的相关性热力图。两列分别代表与人类分数(Human)和与真实评审意见(Reviews)的Pearson相关系数。Clarity 0.78/0.70、Novelty 0.69/0.75、Validity 0.74/0.65、Feasibility 0.64/0.80、Significance 0.55/0.61。Feasibility维度与真实评审意见的相关性最高,达到0.80。
这张热力图值得仔细看。几个有趣的发现:
Feasibility和真实评审的相关性达到0.80——这是所有维度中最高的。为什么?因为可行性是最"客观"的维度:需要多少GPU、数据集够不够大、训练时间能不能接受——这些有明确的判断标准,AI和人类容易达成共识。
Significance的相关性最低(0.55/0.61)——这也在预料之中。"重要性"是一个非常主观的判断,涉及对学科发展方向的理解、对应用前景的预判。两个顶级教授对同一篇论文的重要性评价可能截然相反,AI在这个维度上偏弱完全合理。
Novelty在两列之间反转——和人类直接打分的相关性是0.69,但和真实评审意见的相关性反而更高(0.75)。可能的解释:真实评审意见中包含对新颖性的详细论证("该方法与XXX的区别在于……"),InnoEval的知识搜索恰好能提供类似的对比论据,所以在文本级别的对齐更好。
搜索引擎质量对比
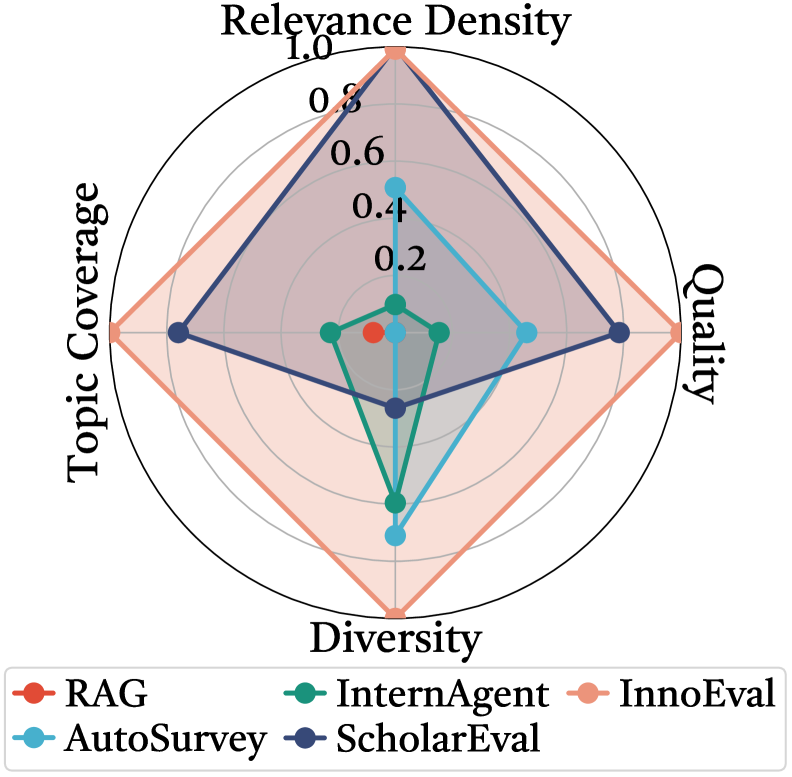
图5:不同搜索方法在五个维度上的表现雷达图。对比了RAG(基础检索增强生成)、InternAgent、InnoEval、AutoSurvey和ScholarEval五种方法,在Relevance(相关性)、Density(密度)、Topic Coverage(主题覆盖率)、Quality(质量)和Diversity(多样性)上的得分。InnoEval在所有维度上都达到或接近最优,雷达图的面积最大。
这个对比很直观。传统RAG的问题很明显——相关性还行,但主题覆盖率和多样性都拉胯,因为它只搜单一数据源。AutoSurvey在Quality上不错(毕竟专注于文献综述),但Diversity很差。InnoEval的雷达图面积最大,说明它在五个维度上取得了最好的平衡。
背后的逻辑也说得通:异构数据源天然带来Diversity和Topic Coverage的优势;迭代精炼确保Relevance和Quality不会因为搜索范围扩大而下降;快慢两阶段搜索保证了Density(检索结果的信息密度)。
评审报告质量

图6:InnoEval与ResearchAgent、ScholarEval生成的评审报告在Problem(问题分析)、Method(方法评估)、Experiment(实验评价)三个维度上的质量对比。InnoEval在三个维度上均达到约4.3-4.4分(5分制),高于两个baseline的约4.0-4.25分。
InnoEval生成的评审报告在问题分析、方法评估和实验评价三方面都优于baseline。差距虽然不算巨大(约0.2-0.3分),但在5分制下稳定领先说明搜索到的知识确实被有效利用了,而不是"搜了很多但评审报告还是空洞的套话"。
Test-time Scaling:审稿人越多,判断越准
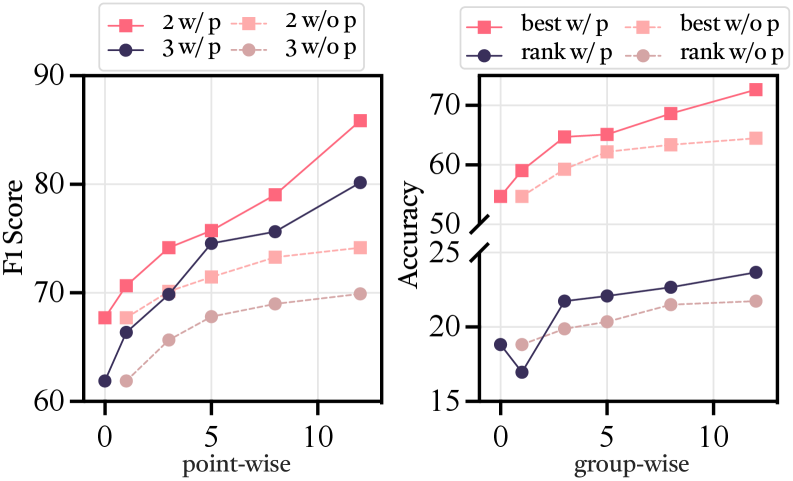
图4:Test-time scaling效果。横轴为虚拟审稿人数量,纵轴为评估准确率。w/p(带个性化角色)和w/o p(不带个性化)两条曲线分别展示了Point-wise(二分类/三分类)、Pair-wise和Group-wise(best/rank)任务上的表现。带个性化的曲线随审稿人数量增加持续上升,而无个性化的曲线很快饱和。
这组实验特别漂亮。两个核心发现:
有个性化角色时,增加审稿人数量会持续提升性能——这和人类评审的规律一致。三个审稿人比一个准,五个比三个准。原因很简单:不同角色的知识储备和评审偏好不同,增加角色数量就是增加视角多样性,更多视角意味着更全面的覆盖。
没有个性化角色时,增加数量很快饱和——都是同一个LLM,加再多"审稿人"也只是在重复类似的判断。随机性带来的微小差异不足以提供真正的多样性。这进一步证明了:个性化角色设计不是噱头,而是test-time scaling能够生效的必要条件。
维度间的相关性和重要性
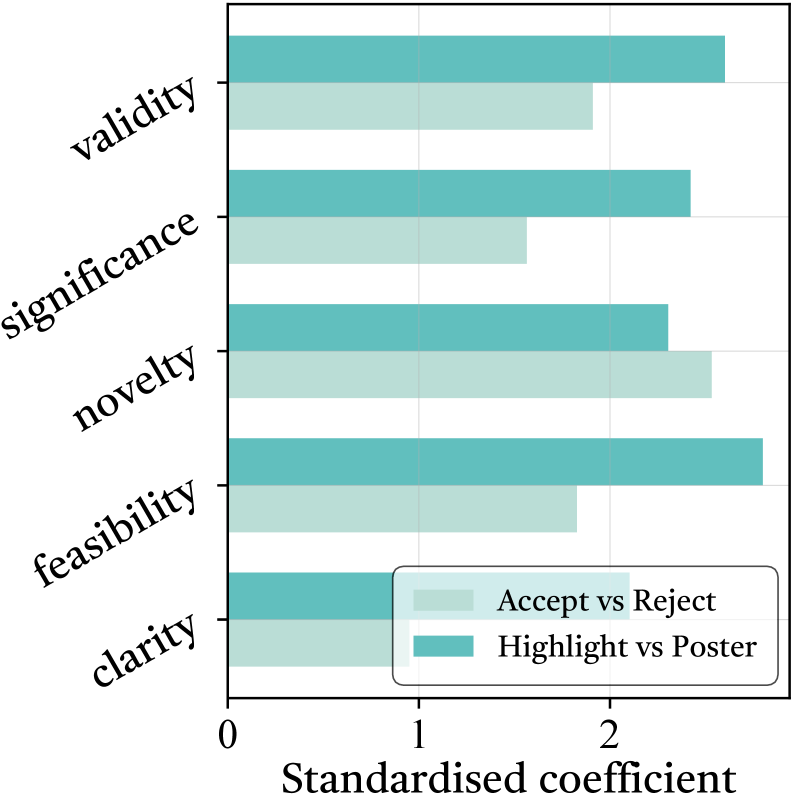
图7:通过线性回归分析五个评估维度对两种决策的影响系数。左侧Accept vs Reject,右侧Highlight vs Poster。在初步接受阶段,各维度的重要性相对均衡,但新颖性权重略高;在从Poster晋升到Highlight(Spotlight/Oral)阶段,Feasibility的系数显著高于其他维度。
这个分析揭示了一个有趣的模式——能被顶会接收和能拿oral/spotlight,靠的是不同的维度。
初审阶段,新颖性是区分Accept和Reject的关键。你提出的东西和别人不同吗?有本质区别还是只是换了个数据集?这是审稿人决定给不给通过的第一道门槛。
但要从Poster级别往上走,Feasibility(可行性)的权重陡增。光是想法新还不够,还得让人相信"这个真的能做出来"。Spotlight和Oral论文往往不只有漂亮的idea,还有扎实的实现和全面的实验——而这些正是可行性维度衡量的东西。
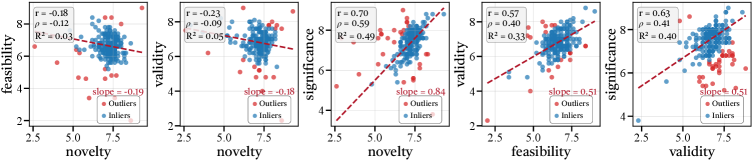
图8:InnoEval评分中五个关键维度对之间的相关性。每张子图展示散点分布、Pearson相关系数r和决定系数R²。novelty-significance的正相关最强(r=0.70, R²=0.49),novelty-validity呈弱负相关(r=-0.23),novelty-feasibility也呈弱负相关(r=-0.18)。feasibility-validity正相关(r=0.57),validity-significance正相关(r=0.63)。
维度间的相关性也很有看头:
Novelty和Significance强正相关(r=0.70)——越新颖的想法往往被认为越重要。这符合学术界的价值观:推动领域发展的是突破性工作,而不是增量改进。
Novelty和Feasibility弱负相关(r=-0.18)——越大胆的想法越不容易实现。这个trade-off在科研中天天遇到:想做点新的,技术路线不成熟;选个稳妥的方向,又担心没有novelty。InnoEval的评分捕捉到了这种张力。
Novelty和Validity也呈弱负相关(r=-0.23)——很新的想法往往缺乏充分的理论验证。毕竟"新"意味着缺少前人的验证积累,有效性还有待证明。
Feasibility和Validity正相关(r=0.57)——能做出来的方法往往也更可能有效。这个关联很好理解:如果方法在工程上可行,通常意味着它建立在成熟的技术基础上,有效性自然更有保障。
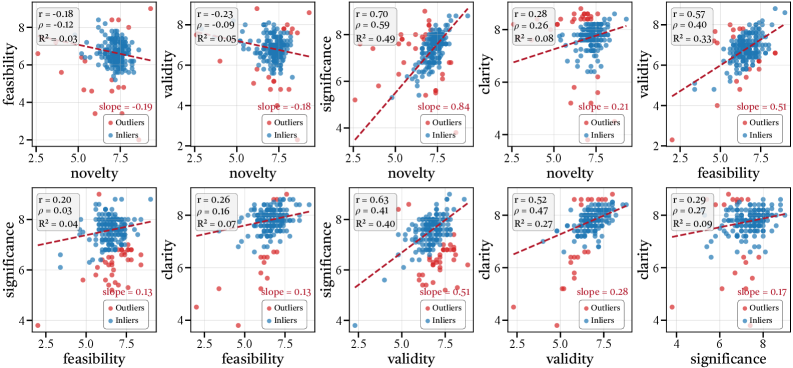
图9:完整的10对维度间相关性散点图矩阵,包含Pearson相关系数r、Spearman等级相关系数ρ和决定系数R²。蓝色点为正常样本(Inliers),红色/黄色三角为离群点(Outliers)。clarity-novelty(r=0.20)、clarity-feasibility(r=0.26)、clarity-validity(r=0.52)、clarity-significance(r=0.29)等更多维度对的关系一目了然。
完整的相关性矩阵补充了更多细节。Clarity和其他所有维度的相关性都是正的(0.20到0.52不等),说明表述清晰度虽然不是决定性因素,但确实能"加分"——写得清楚的论文在每个维度上都倾向于得到更高评价。这也许部分是真实效应(写得清楚说明作者想法成熟),部分是评审心理效应(写得好读起来舒服,打分自然高一些)。
成本和效率
论文给出了实际部署的数据:单个样本的评估成本约$0.42,评估时间约30分钟。
$0.42听起来便宜得不像话——顶会审稿如果按时薪算,一篇论文的审稿成本少说也要几百美元。30分钟的评估时间对实时应用可能偏长,但对于会议投稿的batch评审完全可以接受(反正都要等几个月)。
🤔 我的思考:好设计,但离取代人类审稿人还远着
这篇论文做对了什么
InnoEval最大的贡献不是某个具体模块的设计,而是把评估任务的建模方式改了。从"给LLM一个prompt让它打分"到"搜索-对齐-多视角评估-共识",这个范式转换才是真正有价值的。
多角色评审的设计尤其优雅。test-time scaling那组实验(图4)清楚地证明了:增加角色多样性比增加推理轮数更有效。这和现实世界中的经验完全一致——找一个人反复想三遍,不如找三个不同背景的人各想一遍。
异构知识搜索也做得很扎实。把搜索范围扩展到代码仓库和网页,这个选择看似朴素,但在评估研究想法的可行性时确实提供了文献库不能提供的信息——一个方法在GitHub上有1000 star的开源实现,和一个只存在于论文中的方法,可行性判断天然不同。
但有几个隐忧
评审角色的"天花板"问题。现在的角色是基于预定义模板的——"资深教授,擅长NLP,评审风格严格"。但真正优秀的审稿人之所以能提出深刻的意见,靠的不是"角色标签",而是几十年积累的领域直觉和跨学科视野。用prompt engineering构造的"虚拟教授",能在多大程度上模拟真实教授的思维深度?我持谨慎态度。
从图2的数据看,Significance维度的相关性最低(0.55),恰恰是因为"重要性"这个判断最依赖领域直觉——什么问题值得研究、什么方向代表未来——这些判断超越了知识检索能解决的范围。
快速变化领域的知识时效性。InnoEval的搜索引擎依赖的是某个时间点的知识快照。在AI领域,半年前的SOTA可能已经被刷了好几轮。如果一个想法在搜索时没有找到最新的相关工作(因为还没被索引),可能会被错误地判断为"非常新颖",实际上别人已经做了。这个问题论文没有深入讨论。
评估成本的scaling。\(0.42/样本看起来便宜,但算一下总账:假设一个顶会收到12000篇投稿,全量评估就是\)5040加上6000小时的GPU时间。而且随着搜索迭代次数N的增加、审稿人角色数量的增加,成本是线性甚至超线性增长的。论文展示的test-time scaling效果虽然诱人,但"审稿人越多越好"在实际部署时会碰到成本的硬约束。
一个更大的问题
InnoEval模拟的是"评审"这个单向动作——审稿人看论文、查资料、打分。但真实的同行评审远比这复杂:作者提交论文 → 审稿人质疑 → 作者rebuttal → 审稿人修改意见 → Area Chair综合裁决。这个博弈过程中,很多关键的信息是在对话中产生的——审稿人问了一个问题,作者的回答改变了审稿人的判断。
InnoEval目前完全没有这个交互环节。它更像是"初审意见",而不是完整的评审决策过程。能不能把rebuttal环节也纳入进来——让另一个AI代理扮演"作者"来回应质疑——这也许是值得探索的方向。
令人兴奋的应用可能
尽管有上述限制,InnoEval的实际应用价值不可低估:
科研人员的自我检查工具:在投稿前跑一遍InnoEval,看看自己的想法在哪些维度上薄弱。它不能替代真实的审稿,但可以帮你提前发现明显的问题——比如你自认为很新颖的方法,其实去年已经有三篇类似的了。
会议初审的辅助筛选:不是让AI决定accept/reject,而是用AI标记"这篇论文在新颖性维度上可能有问题,建议审稿人重点检查"。辅助性使用比替代性使用更合理。
想法迭代的反馈引擎:InnoEval搜索到的知识和识别的问题,本身就是优化想法的线索。"评估→发现薄弱点→针对性改进→再评估"——这个闭环如果跑通,可能比评估本身更有价值。
📚 和相关工作的对比
| 方法 | 知识来源 | 搜索策略 | 评估维度 | 偏见缓解机制 | Point-wise 3-class F1 |
|---|---|---|---|---|---|
| LLM-as-Judge(o4-mini) | 模型内部参数化知识 | 无搜索 | 单一/简单聚合 | 无 | ~58% |
| RAG-based评估 | 单一文献库 | 一次性检索 | 可多维度 | 弱 | - |
| ScholarEval | 文献+网页 | 单轮搜索 | 多维度 | 弱 | - |
| ResearchAgent | 文献 | 多轮检索 | 多维度 | 弱 | - |
| InnoEval | 文献+网页+代码 | 快慢迭代+查询精炼 | 五维度解耦 | 多角色共识 | 74.56% |
差距一目了然。InnoEval的领先不是来自某个单点优化,而是搜索深度、知识对齐、多视角评估三个方面协同作用的结果。
⚠️ 局限性
论文自己承认了三点,我再补充一点:
-
学科泛化性未验证。目前只在AI领域测试。但不同学科的评审标准差异极大——医学看临床实验的严格性,物理看理论推导的完备性,社会科学看方法论的合理性。InnoEval能否迁移?搜索引擎需要怎么调整?这些问题还没有答案。
-
效率瓶颈。30分钟/样本对大规模筛选场景是个障碍。虽然可以并行化,但这意味着GPU资源的成本也要乘以并行度。
-
模态局限。只支持文本形式的研究想法。但真实的论文投稿中,架构图、实验结果的可视化、甚至代码都是评审的重要依据。
-
缺乏交互环节。没有模拟rebuttal过程,评估是单向的。在"争议性"论文上(比如审稿人意见分歧很大的那种),单向评估可能不够用。
📝 写在最后
InnoEval这篇工作让我想到一个老笑话:把一只猴子关在房间里足够久,它能打出莎士比亚全集。但如果你给猴子一台电脑、一个搜索引擎、还有几个猴子同事互相讨论——嗯,可能真的可以更快一点。
玩笑归玩笑,InnoEval的核心贡献确实值得认真对待:它证明了"怎么评"比"谁来评"更重要。一个设计合理的评估流程——充分检索知识、精准对齐证据、多角色独立评审、共识机制整合——哪怕每个组件用的都是同一个base model,照样能大幅超越"让最强模型直接打分"的naive方案。
这个insight的迁移价值远超论文评审这个特定场景。任何需要"复杂判断"的AI应用——投资决策、医疗诊断、法律裁判——都可以借鉴这种"知识检索+多视角推理+共识机制"的范式。
当然,距离真正替代人类审稿人还有很长的路。但作为一个辅助工具——帮审稿人预审、帮作者自查、帮会议初筛——InnoEval已经展现出了相当实用的价值。$0.42一次的成本、与人类相关性最高达0.80的准确度,这个性价比很难让人拒绝。
论文信息 - 标题:InnoEval: On Research Idea Evaluation as a Knowledge-Grounded, Multi-Perspective Reasoning Problem - 作者:Shuofei Qiao, Yunxiang Wei, Xuehai Wang 等(浙江大学) - 链接:https://arxiv.org/abs/2602.14367 - 发表时间:2026年2月