你的多智能体系统是"真协作"还是"真烧钱"?一个指标帮你看清真相
3 个 Agent 协作写代码比 1 个 Agent 好了 20%,你很开心——但如果把 3 倍的 token 预算全给 1 个 Agent 让它多想几轮,效果也能一样好呢?这篇论文提出了协作增益指标 \(\Gamma\),帮你照出多智能体系统的真面目。
🎯 一句话总结
这篇论文定义了协作增益 \(\Gamma = \Phi_M / \Phi_S\)(多智能体性能 / 同等资源下单智能体性能),用来区分 MAS 的提升是"协作涌现"还是"资源堆叠",并提出了系统化的因子库和归因范式,把多智能体设计从拍脑袋变成做实验。
📖 一个扎心的问题
ChatDev、MetaGPT、AutoGen……最近两年,基于 LLM 的多智能体系统(MAS)火得不行。一个典型的故事是这样的:
你搭了一个 3 Agent 的代码生成系统——CEO 拆需求、CTO 做架构、Programmer 写代码。一跑,准确率从 27% 提到 34%。你在 PPT 上写下"多智能体协作显著提升性能",信心满满。
但这里有个问题:3 个 Agent 吃了大约 3 倍的 token。假如把同样的 token 预算全给一个 Agent,让它用 Chain-of-Thought 多推理几轮呢?如果单 Agent 在同样预算下也能到 34%,那你的"多智能体系统"本质上只是个"多花钱系统"——协作并没有带来额外的东西。
这就是 MAS 领域的"皇帝新衣"问题:大家都在说协作好,但没人严格证明好处到底来自协作还是来自更多计算资源。
这篇来自上海交大、复旦、清华联合团队的论文,直面了这个问题。它的核心立场很明确:MAS 需要从"盲目试错"走向"严谨科学",而第一步就是建立一个科学的度量标准。
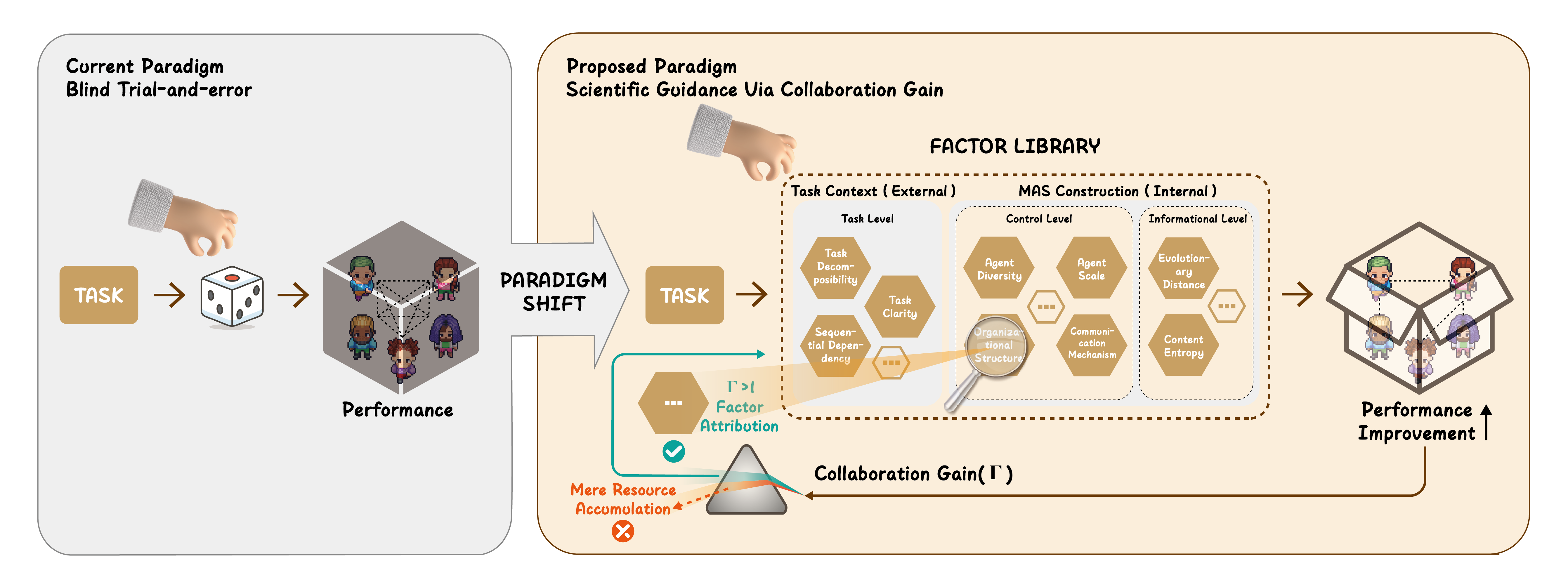
图1:左侧是当前的"黑盒"范式——往 MAS 里塞各种设计,性能提升了但不知道为什么;右侧是论文提出的"白盒"范式——通过协作增益 \(\Gamma\) 这个"棱镜",把性能提升分解为"真协作"和"假繁荣",然后做因子归因。
🔬 核心武器:协作增益 \(\Gamma\)
灵感来源:涌现理论
论文借鉴了复杂系统科学中的一个经典概念——涌现(Emergence):整体大于部分之和。
蚁群中每只蚂蚁的行为很简单(闻到信息素就跟着走),但整个蚁群能找到最短路径。这种"个体能力之和 < 集体表现"的现象就是涌现。
对 MAS 来说也一样:真正有价值的协作,应该让多个 Agent 一起做到单个 Agent 做不到的事——哪怕给单个 Agent 同样多的资源也做不到。
公式定义
- \(\Phi_M\):多智能体系统的集体性能
- \(\Phi_S\):资源等效条件下单智能体系统能达到的最佳性能
"资源等效"是关键。如果你的 MAS 用了 3 个 Agent、总共烧了 60,000 tokens,那计算 \(\Phi_S\) 时,就要给单个 Agent 同样的 60,000 tokens 预算,还要让它用上 CoT、Self-Reflection 等策略来"充分利用"这些 token,确保基线足够强。
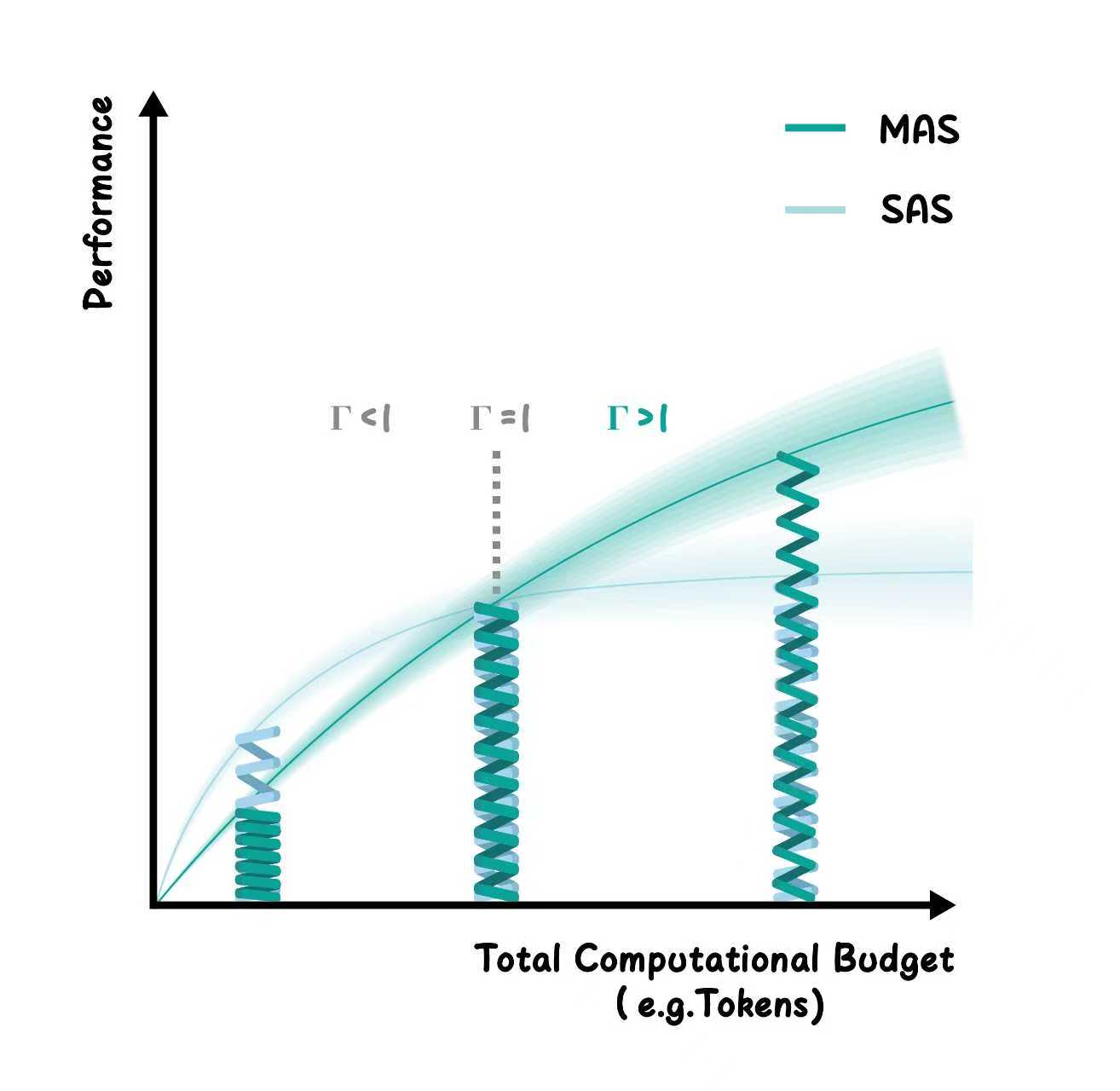
图2:横轴是总计算预算(如 token 数),纵轴是性能。蓝线是 MAS,红线是单 Agent。只有当 MAS 曲线显著高于单 Agent 曲线时(\(\Gamma > 1\)),才说明协作产生了真正的增益。如果两条线重合(\(\Gamma = 1\))或 MAS 更低(\(\Gamma < 1\)),说明多 Agent 没帮上忙、甚至帮了倒忙。
怎么判断?
| \(\Gamma\) 值 | 含义 | 直白解释 |
|---|---|---|
| \(\Gamma > 1\) | ✅ 协同效应 | 协作产生了"1+1>2"的效果,多 Agent 确实比单 Agent 强 |
| \(\Gamma = 1\) | ⚠️ 零增益 | 性能提升全来自多花的资源,协作没有额外贡献 |
| \(\Gamma < 1\) | ❌ 负效应 | 协作反而拖后腿,还不如把资源全给一个 Agent |
\(\Phi_S\) 怎么算?不同任务不一样
这里有个技术细节值得展开。论文在附录 B 中详细讨论了不同任务类型下 \(\Phi_S\) 的计算方式:
累积任务(比如多目标跟踪):总预算分给多个独立单 Agent 实例,\(\Phi_S\) 是它们贡献之和。如果 \(\Gamma > 1\),说明协作(如动态分工)带来的收益超过了协调成本。
覆盖任务(比如数学题集):\(\Phi_S\) 对应"等效采样广度"——给单 Agent 同样的 token 预算,让它通过 Self-Consistency 做 \(k\) 次独立采样。这确保 \(\Gamma\) 测的是"协作带来的推理穿透",而不是"多试几次碰运气"。
单解任务(比如代码生成):\(\Phi_S\) 代表"深思熟虑后的个体极限"——单 Agent 拿到全部预算,用最深的 CoT 和 Self-Reflection。这捕获的是:多 Agent 交互是否真正实现了超越个体能力上限的非线性飞跃。
🧪 实验验证:三个阶段,三个故事
论文在附录 D 中做了一个漂亮的案例研究,用 SRDD 数据集中的"Navigation Buddy"任务(一个实时导航系统的代码生成)来验证 \(\Gamma\) 的诊断能力。
实验统一使用 Qwen3-30B 系列模型,严格控制 token 预算上限为 20,000。评估指标是软件质量 \(Q = \text{completeness} \times \text{executability} \times \text{consistency}\)。
阶段一:角色分工有用吗?
配置:3 个 Agent 组成链式结构(CEO → CTO → Programmer),全部用 Qwen3-30B
| 指标 | 单 Agent (SAS) | 多 Agent (MAS) |
|---|---|---|
| 完整性 | 0.35 | 0.42 |
| 可执行性 | 1.00 | 1.00 |
| 一致性 | 0.76 | 0.81 |
| 软件质量 Q | 0.27 | 0.34 |
| 协作增益 \(\Gamma\) | — | 1.26 |
\(\Gamma = 1.26 > 1\)!角色分工带来了真正的协作增益。CEO 负责理解需求、CTO 负责架构设计、Programmer 负责实现——这种分工让系统超越了"给一个 Agent 同样多 token"能达到的水平。
这说明什么?角色多样性是一个正因子。 不同 Agent 扮演不同角色时,会从不同视角审视问题,产生互补效应。
阶段二:换个专业模型呢?
配置:把 Programmer 换成 Qwen3-Coder-30B(专门的代码模型)
| 指标 | 单 Agent (SAS) | 多 Agent (MAS) |
|---|---|---|
| 完整性 | 0.35 | 0.60 |
| 可执行性 | 1.00 | 1.00 |
| 一致性 | 0.76 | 0.83 |
| 软件质量 Q | 0.27 | 0.50 |
| 协作增益 \(\Gamma\) | — | 1.85 |
\(\Gamma\) 从 1.26 飙升到 1.85!引入专用代码模型后,完整性从 0.42 跳到 0.60——提升幅度非常可观。
论文的分析很到位:这不只是"用了个更好的模型"那么简单。关键在于异构协作——通用模型负责高层理解和架构规划,专用模型负责底层编码实现。这种组合产生了"功能正确性"到"工程抽象"的能力跃迁,而不是简单的 1+1。
阶段三:多加几个 Agent 会更好吗?
配置:把 Agent 从 3 个扩到 5 个,保持顺序链结构
| 指标 | 单 Agent (SAS) | 多 Agent (MAS) |
|---|---|---|
| 完整性 | 0.35 | 0.23 |
| 可执行性 | 1.00 | 1.00 |
| 一致性 | 0.76 | 0.74 |
| 软件质量 Q | 0.27 | 0.17 |
| 协作增益 \(\Gamma\) | — | 0.63 |
\(\Gamma = 0.63\),协作增益崩溃了。 不仅没帮上忙,反而拖了后腿——5 个 Agent 的表现还不如 1 个 Agent。
为什么?论文用信息层面的动态分析给出了解释。
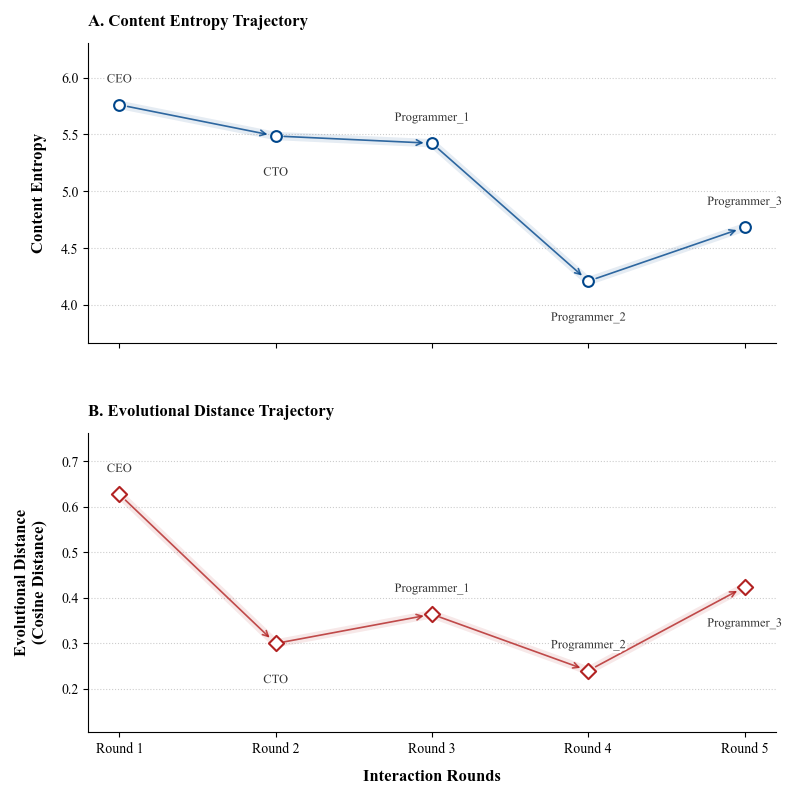
图8:上图是内容熵轨迹,下图是演化距离轨迹。注意看 Programmer_1 到 Programmer_2 之间发生了什么——内容熵突然回升,演化距离也出现跳变。这意味着信息流在长链条中断裂了。
问题出在上下文过载。在 5 Agent 的长链条中,每个 Agent 需要理解前面所有 Agent 的输出。到了第 4、5 个 Agent,前面积累的信息已经超出了上下文窗口的有效承载能力。后续 Agent 被迫"简化"理解,丢失了关键的架构信息,最终输出质量反而下降。
这和 MacNet(MACNET)的研究发现遥相呼应。MacNet 提出了多智能体协作中的"小世界"现象和协作缩放定律——Agent 数量并非越多越好,存在一个最优规模区间。超过这个区间后,协调开销会吞噬协作收益。
三个阶段的实验结果放在一起看,故事很清楚:
| 阶段 | 改变的因子 | \(\Gamma\) | 结论 |
|---|---|---|---|
| I | 引入角色多样性 | 1.26 | ✅ 正因子 |
| II | 引入模型异质性 | 1.85 | ✅ 正因子(效果更强) |
| III | 盲目扩大规模 | 0.63 | ❌ 负因子 |
🗺️ 因子库:给 MAS 设计画一张地图
光有 \(\Gamma\) 还不够。你知道了某个配置好不好用,但不知道该往哪个方向调。论文的第二个贡献是构建了一个系统化的因子库——把 MAS 的设计空间整理成一张可导航的地图。
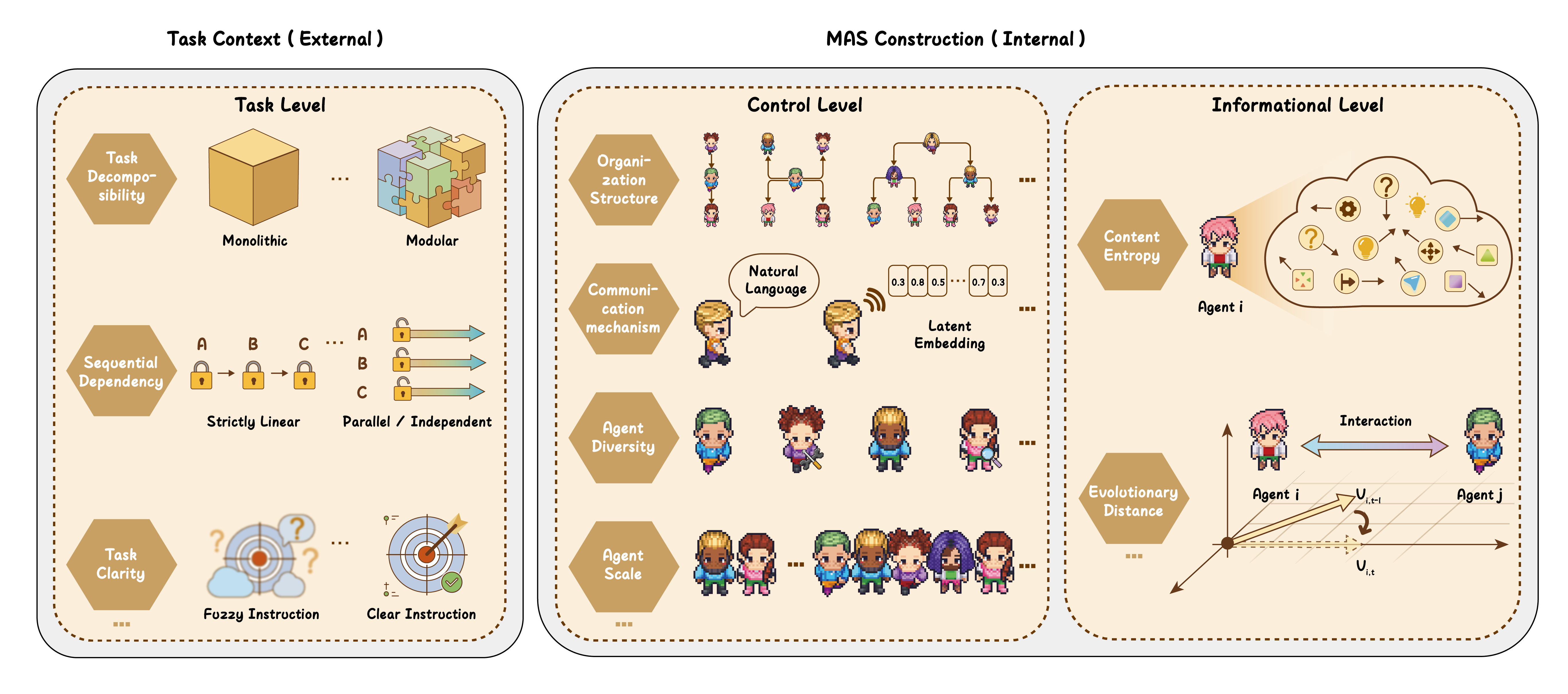
图3:因子库的全景图。左侧是外部的任务上下文因子(任务本身的特点),右侧是内部的 MAS 构建因子(你能控制的设计变量)。内部因子又分为静态的"控制层"(架构预设)和动态的"信息层"(运行时状态)。
外部因子:任务特征决定了 MAS 的天花板
在动手搭 MAS 之前,先看看你的任务适不适合多 Agent 协作。论文整理了几个关键的任务维度:
任务可分解性——任务能不能拆成相对独立的子任务?如果任务天然就是一整块(比如证明一个定理),强行拆开让多个 Agent 做可能适得其反。Finance Agent 的成功案例表明,高可分解性的金融分析任务天然适合通过集中式协调器分配子任务并行执行。
顺序依赖性——子任务之间是必须串行,还是可以并行?MM-Agent 的四阶段流程表明,有严格顺序依赖的任务需要精心设计信息传递机制。
任务清晰度——指令是模糊的还是精确的?模糊指令下,多 Agent 的"理解偏差"会被放大;而清晰指令下,分工协作更容易产生增益。
内部因子:控制层——你能拧哪些旋钮
1. 组织结构
不同的拓扑带来不同的效果。论文做了专门的对比实验:
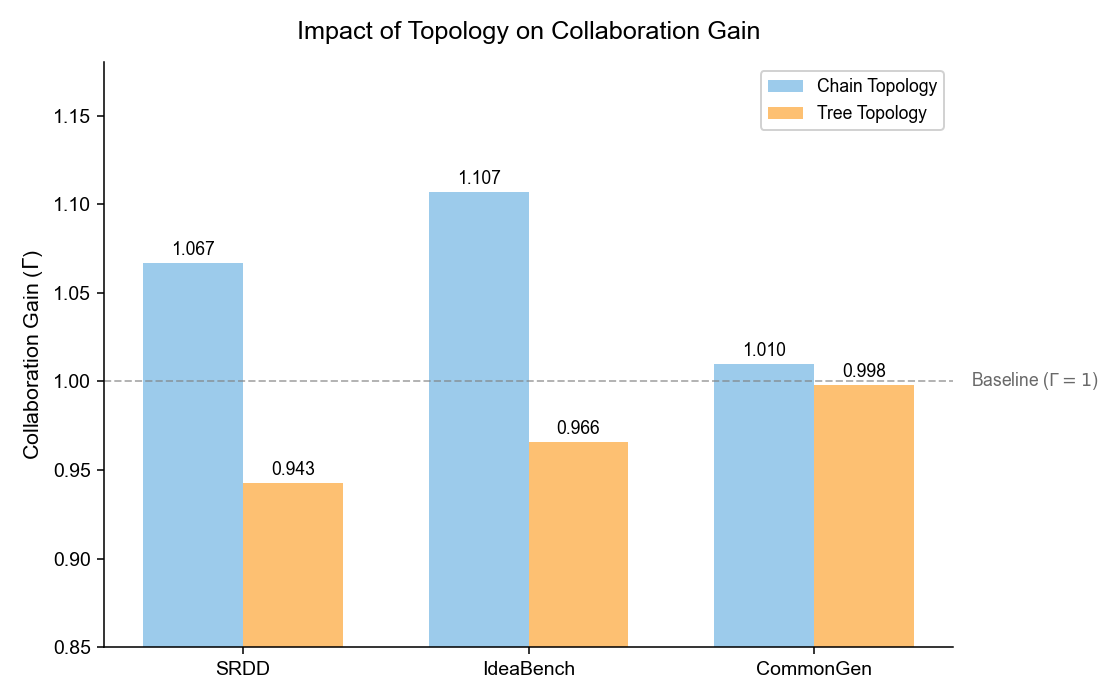
图7:在 SRDD、IdeaBench、CommonGen 三个数据集上,链式拓扑 vs 树形拓扑的 \(\Gamma\) 对比。链式在 SRDD 和 IdeaBench 上 \(\Gamma > 1\),但树形拓扑在多数场景下 \(\Gamma < 1\)。
链式拓扑(A→B→C→D→E)让信息逐层积累,适合需要渐进式细化的任务。而树形拓扑(在某个节点分支)虽然理论上能并行处理,但分支路径之间的协调开销在这些实验中超过了并行化的收益。
这并不是说树形结构总是差。ChatEval 用多 Agent 辩论拓扑在评估任务上取得了好效果,MindAgent 用集中式协调在需要实时分配的游戏任务中表现出色。拓扑没有万能解,得配合任务特性来选。
论文引用了多种组织结构优化方案:
| 方法 | 策略 | 特点 |
|---|---|---|
| Puppeteer | 基于强化学习的动态编排 | RL 训练的编排器动态调整 Agent 交互顺序 |
| ChatEval | 多 Agent 辩论拓扑 | 通过自主多轮论证综合不同视角 |
| MindAgent | 集中式任务协调 | 动态调度任务、分发指令 |
| MASS | 交错设计优化 | 迭代优化 prompt、拓扑和全局配置 |
| MaAS | 基于超网的架构搜索 | 从概率超网中动态采样依赖查询的架构 |
2. 通信机制
Agent 之间怎么交流信息,直接影响协作效率。论文梳理了三种主要方式:
- 显式自然语言通信:最直观,Agent 之间直接"说话"。但 token 消耗大,长链条容易信息过载。
- 潜在空间通信:LatentMAS 提出了一种免训练方案,建立共享的潜在工作记忆,Agent 之间直接传递 embedding 而非文本。这绕过了自然语言的信息瓶颈。
- 压缩通信:AgentPrune 在时空消息传递图上做一次性修剪,去掉冗余交互;Entropy-Debate 用熵压缩来提升通信效率。Optima 则通过 SFT/DPO 训练,用 token 消耗作为 reward 的一部分来约束通信成本。
3. 智能体多样性
阶段一和阶段二的实验已经说明了多样性的力量。这里再补充几个典型方案:
- X-MAS:基于领域能力把不同的 LLM 分配给不同角色——比如让擅长推理的模型做规划,擅长代码的模型写代码。
- MoA(Mixture-of-Agents):在多层结构中编排多样化的 LLM,每层 Agent 关注上一层的集体输出来迭代细化。
- LLM-Blender:通过成对排名和生成融合来聚合多样化模型的输出。
4. 智能体规模
阶段三已经用血淋淋的 \(\Gamma = 0.63\) 告诉我们:规模不是越大越好。这和 2024 年初"More Agents Is All You Need"的乐观论调形成了有趣的对比——该研究发现 LLM 性能可以随 Agent 数量增加而提升,但它主要关注的是覆盖任务(通过 majority voting 提升准确率),本质上是"多采样"而非"真协作"。
MacNet 的 DAG 拓扑和 MegaAgent 的动态扩展提供了更精细的规模控制方案——不是简单堆人头,而是根据任务复杂度动态调整规模。
内部因子:信息层——运行时能看到什么
除了静态的架构预设,论文还提出了两个动态指标来监测运行时的协作状态:
内容熵 \(H_t\)
把它想象成"方案的不确定性温度计"。协作刚开始时,Agent 们还在探索,方案很不确定,\(H_t\) 高。随着交互推进,方案逐渐收敛,\(H_t\) 应该单调下降。
如果 \(H_t\) 半路突然回升——就像图 8 中 Programmer_1 到 Programmer_2 那段——说明信息流出了问题,后续 Agent 丢失了前面建立的共识,又开始"重新探索"了。
演化距离 \(D_t\)
这个公式看着复杂,直觉上很简单:每一轮交互之后,Agent 的"想法"变化了多少? 它用的是余弦距离——两个时间步之间状态向量的偏移程度。
\(D_t\) 高说明交互带来了显著的思路变化(好事,说明 Agent 在互相学习)。\(D_t\) 持续为零说明大家只是在互相重复,协作是无效的。但 \(D_t\) 突然飙高(如图 8 中链条断裂时),则是危险信号——说明信息传递出了问题,后续 Agent 被迫"另起炉灶"。
🔄 因子归因范式:把 MAS 优化变成做实验
有了 \(\Gamma\) 作为度量工具、有了因子库作为搜索空间,论文提出了一套系统的优化方法论:
这套方法和科学实验的逻辑一模一样:
| 科学实验 | MAS 优化 |
|---|---|
| 控制变量法 | 一次只改一个因子 |
| 测量仪器 | \(\Gamma\) 值 |
| 显著性检验 | \(\Gamma > 1\) 还是 \(\leq 1\) |
| 归因分析 | 该因子是正因子还是负因子 |
不再是拍脑袋说"加个 Agent 试试",而是带着假设、做实验、看数据、得出结论。
🌍 从自然界偷师:生物与人类社会的集体智能
论文附录中用了大量篇幅讨论自然界和人类社会中的集体智能,为 MAS 设计提供灵感。这部分挺有意思的。

图4:生物世界中的通信方式远比我们想象的丰富——从蚂蚁的化学信息素、蜜蜂的摇摆舞,到海豚利用水流协作围捕鱼群,再到大象用次声波跨距离协调行动。这些"通信机制"的多样性启发了 MAS 中除自然语言之外的通信方案设计。
生物系统的三种组织模式
| 模式 | 代表 | 特点 | 对 MAS 的启发 |
|---|---|---|---|
| 去中心化 | 鸟群、鱼群 | 无领导者,每个个体只遵循局部规则 | 简单规则 + 大规模 → 涌现全局智能 |
| 中心化 | 狼群 | 有明确的 Alpha 领导 | 复杂协调任务需要"指挥官" |
| 混合型 | 蜜蜂 | 平时去中心化采蜜,关键决策(选巢)时投票集中 | 动态切换可能是最优解 |
蚁群优化(ACO)和粒子群优化(PSO)这些经典算法就是从这些生物系统中抽象出来的。
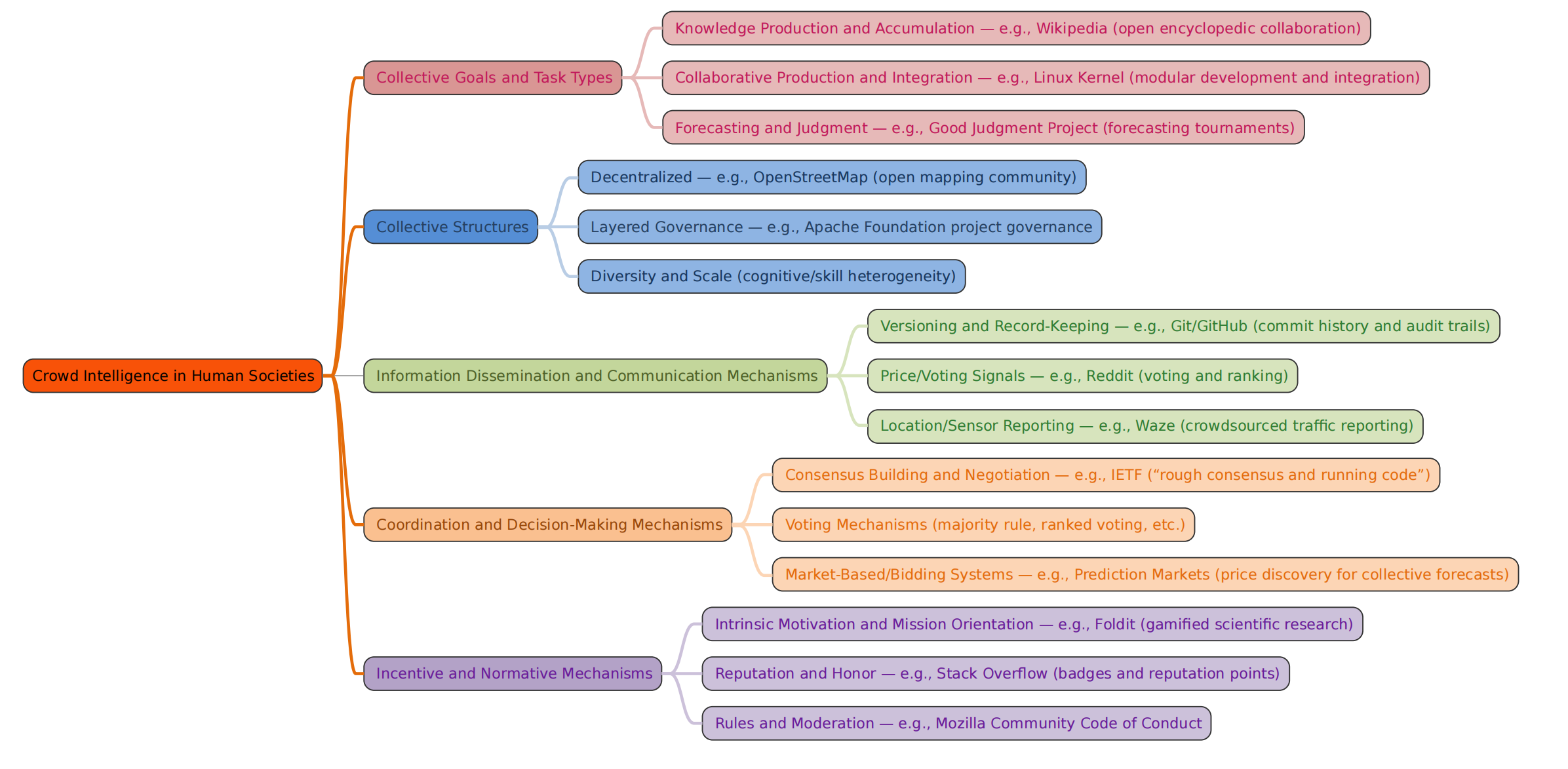
图5:人类社会实现集体智能的五大维度——群体目标与任务类型、群体结构、信息扩散与沟通、协调与决策、激励与规范。每个维度都有丰富的实际案例。
人类社会的经验
论文对比了几个经典案例:
| 案例 | 结构 | 协调方式 | 成功要素 |
|---|---|---|---|
| Wikipedia | 开放、扁平 | 共识编辑、版本回退 | 低门槛参与 + 严格质量控制 |
| Linux | 层级 + 模块化 | 代码审查、贡献者等级 | 明确的贡献路径和晋升机制 |
| Waze | 去中心化众包 | 位置/传感器报告 | 用户越多数据越准的正反馈 |
| 预测市场 | 去中心化 | 价格信号聚合 | 用经济激励对齐信息贡献 |
| Foldit | 游戏化科研 | 竞争 + 协作 | 内在动机(科学使命感)+ 游戏趣味 |
这些案例的一个共同点是:成功的集体智能系统都有明确的激励机制来对齐个体行为和群体目标。当前的 LLM MAS 在这方面几乎是空白——Agent 们并没有"动机"去协作,只是按照 prompt 指令在做事。这可能是未来研究的一个重要方向。
🤔 三个常见质疑与回应
论文坦诚地回应了三个可能的批评:
"算 \(\Gamma\) 太麻烦了,还要额外跑单 Agent 基线"
没错,算 \(\Phi_S\) 确实需要额外实验。但如果你只看准确率,你永远分不清提升来自哪里。就像体检——抽血化验确实麻烦,但能帮你发现潜在问题。\(\Gamma\) 提供的透明度值得这个成本。
"把系统拆成因子太还原论了,忽略了因子间的交互"
这个批评有道理。真实系统中因子是互相耦合的。但科学研究就是这样——先识别单因子的作用,再研究交互效应。牛顿力学也是先分析单个力,再合成合力的。因子库是"分析地图",不是"设计模板"。
"因子归因只是相关性,不是因果性"
确实,当前方法还停留在"发现哪些因子与高 \(\Gamma\) 相关"的层面。但这是通向因果建模的必要起点。先发现相关性,再用干预实验和因果推断方法验证因果关系——这是科学研究的标准路径。
💡 我的思考
1. \(\Gamma\) 打破了 MAS 领域的"自嗨"
做 MAS 的人(包括我在内)都容易犯一个错误:多加了几个 Agent、效果好了一点,就认为"多智能体协作果然有用"。但不设置资源等效的基线,这个结论就是站不住脚的。
\(\Gamma\) 是一面照妖镜。回想一下最近的很多 MAS 论文——如果严格计算 \(\Gamma\),有多少能真正大于 1?我持悲观态度。很多所谓的"协作增益",恐怕只是"多花了几倍的 token"而已。
2. 计算 \(\Phi_S\) 的灰色地带
论文提出的框架很优美,但工程落地时有个棘手的问题:怎么定义"资源等效的单 Agent"?
比如 MAS 用了 3 个不同模型的 Agent(一个 GPT-4o、一个 Claude、一个 Qwen-Coder),那单 Agent 基线用哪个模型?用最强的那个?用三个的平均能力?
论文给出了一个原则:单 Agent 基线必须使用 MAS 中最强的模型。但"最强"本身就不好定义——GPT-4o 推理强、Qwen-Coder 写代码强,"最强"取决于任务。
3. 拓扑实验的一个疑问
链式拓扑在多数任务上 \(\Gamma > 1\),树形拓扑 \(\Gamma < 1\)。但这个结论有个前提:实验中的树形拓扑是"分支后不合并"的简单分叉。如果用带合并节点的 DAG 结构(类似 MapReduce),结果可能完全不同。MacNet 的 DAG 拓扑在大规模场景下是有效的。
所以更准确的结论应该是:简单的分叉不如线性积累,但精心设计的分支-合并结构可能是另一回事。
4. 信息层指标的实用前景
内容熵 \(H_t\) 和演化距离 \(D_t\) 让我很兴奋。它们提供了一种运行时监测协作健康度的方法——不用等到最终结果出来,在协作过程中就能判断"这轮交互有没有用"。
想象一下:一个 MAS 系统在跑的时候,如果检测到 \(H_t\) 突然回升或 \(D_t\) 持续为零,就自动触发干预(比如换一个 Agent、调整拓扑、插入新的 prompt 指令)。这种"自适应 MAS"可能是这套理论框架最有工程价值的落地方向。
5. 对工程实践的建议
如果你正在设计一个 MAS 系统,这篇论文的启示可以浓缩成三条:
- 永远先跑单 Agent 基线:给单 Agent 和你的 MAS 同样的 token 预算,确保基线足够强。如果单 Agent 就够用,别折腾 MAS。
- 一次只动一个旋钮:改了角色分配、改了拓扑结构、又换了模型——性能变了你也不知道归功于谁。控制变量,逐步迭代。
- 监控 \(\Gamma\),别只看准确率:准确率从 70% 到 75% 看起来很好,但如果 \(\Gamma < 1\),说明你花了更多资源却没有真正的协作收益。
📊 论文关键信息卡
| 项目 | 内容 |
|---|---|
| 标题 | Towards a Science of Collective AI: LLM-based Multi-Agent Systems Need a Transition from Blind Trial-and-Error to Rigorous Science |
| 机构 | 上海交通大学、复旦大学、清华大学、伦敦国王学院、鹏城实验室 |
| 核心贡献 | 协作增益 \(\Gamma\)、因子归因范式、MAS 因子库(控制层 + 信息层) |
| 关键实验 | 角色多样性 \(\Gamma=1.26\) ✅、模型异质性 \(\Gamma=1.85\) ✅、盲目扩规模 \(\Gamma=0.63\) ❌ |
| 拓扑实验 | 链式 \(\Gamma > 1\)(SRDD/IdeaBench)、树形 \(\Gamma < 1\)(多数场景) |
| 信息层指标 | 内容熵 \(H_t\)(方案确定性)、演化距离 \(D_t\)(语义位移强度) |
| 论文链接 | https://arxiv.org/abs/2602.05289 |
🔗 延伸阅读
- MacNet:多智能体协作网络,提出了协作缩放定律和小世界现象
- ChatDev:瀑布模型驱动的软件开发 MAS(CEO/CTO/Programmer/Tester)
- MetaGPT:将 SOP 嵌入多智能体协作,ICLR 2024 Oral
- AutoGen:微软的多智能体对话框架,支持灵活的拓扑配置
- "More Agents Is All You Need":Agent 数量与性能的缩放关系研究
- LatentMAS:免训练的潜在空间通信,突破自然语言通信瓶颈
如果觉得有用,欢迎点赞、在看、转发三连~